Blocking HTTP requests
The most popular and easy to use blocking http client for python is requests. The requests docs are simple and straight forward…for humans.
The biggest performance gain you can acquire (provided you are making requests to a single host) is using an http session. This creates a persistent connection, meaning that additional requests will use the existing session and avoid an additional TCP handshake and maybe SSL handshake. More info on that in this blog post on python and fast http clients.
Example Blocking HTTP persistent connection vs new connections
Here is some example code for getting quotes from quotes.rest
import requests
import time
def get_sites(sites):
data = []
session = requests.Session()
for site in sites:
response = session.get(site)
data.append(response.json())
return data
if __name__ == '__main__':
categories = ["inspire", "management", "sports", "life", "funny", "love", "art", "students"]
sites = [
f'https://quotes.rest/qod?category={category}' for category in categories
]
start_time = time.time()
data = get_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")
Don’t overuse this API as they have rate limits and will eventually give you a 429 http status code as a response – Too Many Requests
So when I run this code:
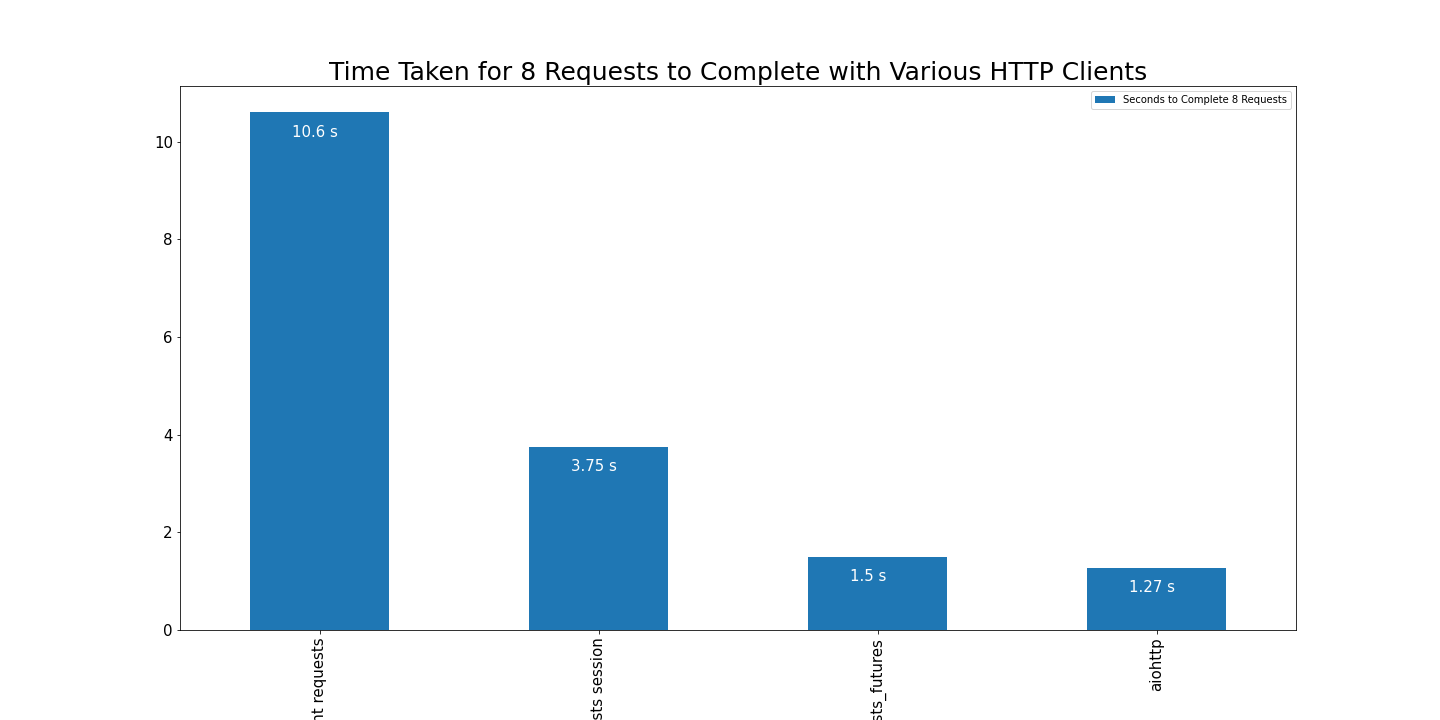
Downloaded 8 sites in 3.7488651275634766 secondsThat is pretty fast, but what would be the case if I used requests.get() instead of using the session?
In that case the result was:
Downloaded 8 sites in 10.602024793624878 secondsSo in the first example reusing the existing HTTP connection was 2.8 times faster.
Threaded HTTP Requests
There is a library that uses requests called requests_futures that uses threads – preemptive multi-threading.
Example Threaded Request Futures
from concurrent.futures import as_completed
from requests_futures import sessions
import time
def get_sites(sites):
data = []
with sessions.FuturesSession() as session:
futures = [session.get(site) for site in sites]
for future in as_completed(futures):
resp = future.result()
data.append(resp.json())
return data
if __name__ == '__main__':
categories = ["inspire", "management", "sports", "life", "funny", "love", "art", "students"]
sites = [
f'https://quotes.rest/qod?category={category}' for category in categories
]
start_time = time.time()
data = get_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")When running this code it was faster:
Downloaded 8 sites in 1.4970569610595703 secondsInterestingly if I set the max workers to 8 sessions.FuturesSession(max_workers=8), it slows it down dramatically;
Downloaded 8 sites in 5.838595867156982 secondsAnyway the threaded requests is 7 times faster than non-persistent blocking http and 2.5 times fast than persistent blocking http.
Asynchronous HTTP Requests
The next thing to look at is co-operative multi-tasking, which still uses a single thread (and single process) but will give control of execution back to the event loop once’s it is done – it won’t block. Bypassing the negative effects of the python GIL (Global Interpreter Lock).
Python has a few async http libraries: aiohttpand httpx
Example Async Aiohttp
from aiohttp import ClientSession
import asyncio
import time
async def get_sites(sites):
tasks = [asyncio.create_task(fetch_site(s)) for s in sites]
return await asyncio.gather(*tasks)
async def fetch_site(url):
async with ClientSession() as session:
async with session.get(url) as resp:
data = await resp.json()
return data
if __name__ == '__main__':
categories = ["inspire", "management", "sports", "life", "funny", "love", "art", "students"]
sites = [
f'https://quotes.rest/qod?category={category}' for category in categories
]
start_time = time.time()
data = asyncio.run(get_sites(sites))
duration = time.time() - start_time
print(f"Downloaded {len(sites)} sites in {duration} seconds")The result of this code was:
Downloaded 8 sites in 1.271439790725708 secondsThat is the fastest response we have had yet. More than 8 times faster than the non-persistent blocking HTTP connection, almost 3 times faster than the persistent blocking HTTP connection.
Also 17% Faster than the threaded blocking HTTP requests.
Thoughts on Aiohttp
The problem with aiohttp as rogouelynn mentions in a blog post is everything needs to be async
In real life scenarios you often need to do some syncronous stuff first, like authenticating and receiving a token.
You can’t just do:
session = ClientSession()
response = session.get('https://iol.co.za')
>>> response
As you only get back a context manager.
Potentially an easier to use library is httpx because syncronous requests are as native and easy to do as asynchronous requests.
r = httpx.get('https://httpbin.org/get')Putting it all together
How to speed up http calls in python…well go through the steps until you get the speed you need.
- Use simple blocking persistent HTTP connections with
requests.Session() - Use an Asynchronous http client like
asyncioorhttpx.
In the steps above I skip over the threading part as you will find that when you scale up threading can become unreliable and it is usually the case where async is better or matches threading performance.