How often is it the case where monitoring alerts and notifications get out of hand in an organisation.
- The alerts become too many
- Alert only via a single channel
- Alert for minor and major severity in the same manor
This takes time off engineers hands for improving and fixing systems when they constantly have to check these alerts and make decisions based on how important they are etc.
Ideally, alerts should be relevant for things that need to be fixed in a short time frame. Other alerts (non-critical) still may be good but should be reviewed looking back over a longer period. Perhaps as silent log entries that have a monthly report for future projects to correct. That is how I see it at least…
The key things to get right in my opinion:
- Relevancy: disregard irrelevant alerts for the present
- Channels: Sending critical alerts to instant messaging / phone calls and non-critical to email / analytics platform
- Structured data – alerts should be as structured as possible so it lets you make specific criteria and rules based on them. If the data you receive is garbage text (like an email) then you won’t have a good way of classifying and remediating from them. There should be a generic format all alerts can fall into.
- Versatile = Let the various departments own their rules / criteria – the people running these systems are the ones that should receive the alerts and manage the channel, severity etc.
- Machine learning? – Can other automated rules or dare I say it Machine learning make decisions on severity of alerts and assist in classification
A Note on Machine Learning
Naturally we want this all done for us at the click of a button, but it is not that easy. Some people will just shout machine learning or AI will handle it, without the slightest idea of what that entails.
Leveraging machine learning (specifically supervised) I think is the way to go. This way you train the machine to identify critical / relevant messages – with a human. Much like how Google uses Captcha to train robots to identify bus stops and shop entrances or read books. Making structured data from unstructured….
I thought having a user assign a severity level, 1 to 5 based on each alert from each relevant department for a while will help a machine learning algorithm identify important and not important messages.
Unfortunately I have not seen a system like this in the wild – it may have to be a custom system to be developed…
What Can you do now to control your alerts?
You need to keep all your alerts first, store them so that you can run analytics on them later for more insight.
Store all the things…
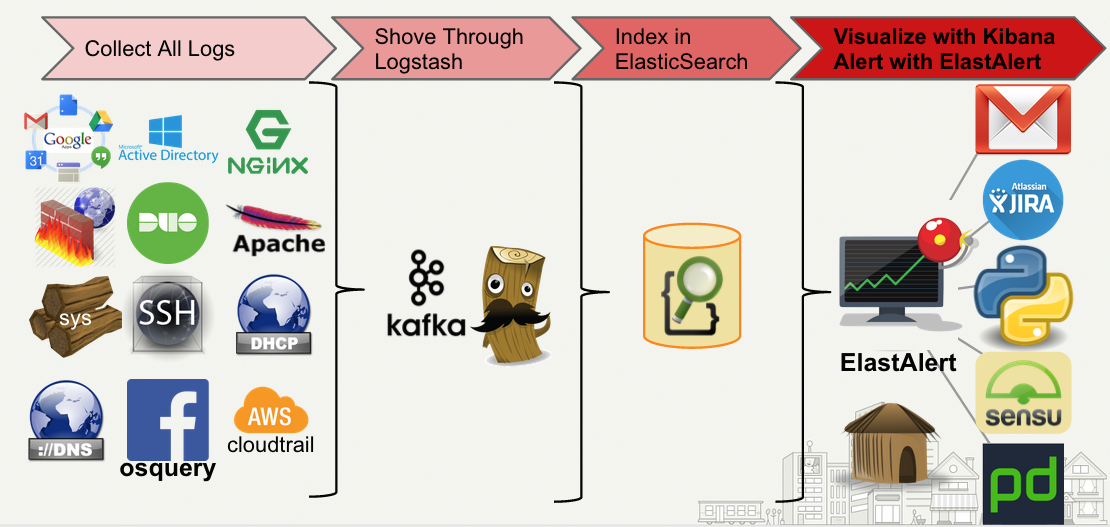
Picture taken from: https://engineeringblog.yelp.com/2016/03/elastalert-part-two.html
You also want the ability to add rules / criteria easily to the alerts coming in, and you want this to be easy enough for non-developers to create and manage them.
If you look at the image above you want to collect all the data you can (so prefer to get it direct from the system, instead of the monitoring systtem controlling the alerts).
So use elasticsearch…bottomline. That is the ELK stack (you could also try using the TICK-L stack). We just need to figure out what we want to interact with it in terms of creating rules, criteria and possible machine learning for it.
- elastalert
- 411
- LoudML
- Sentinl
- Praeco – frontend for elastalert
- Elastalert Kibana Plugin
- X-Pack (Pay for Elastic stack extension)
Tutorials:
- Devops Tutorial to setup intelligent machine learning alerts
- Machine Learning alerts with PagerDuty LoudML
- Using 411 for security alerting
- Elastalert tutorial
The Proof however is in the Tasting
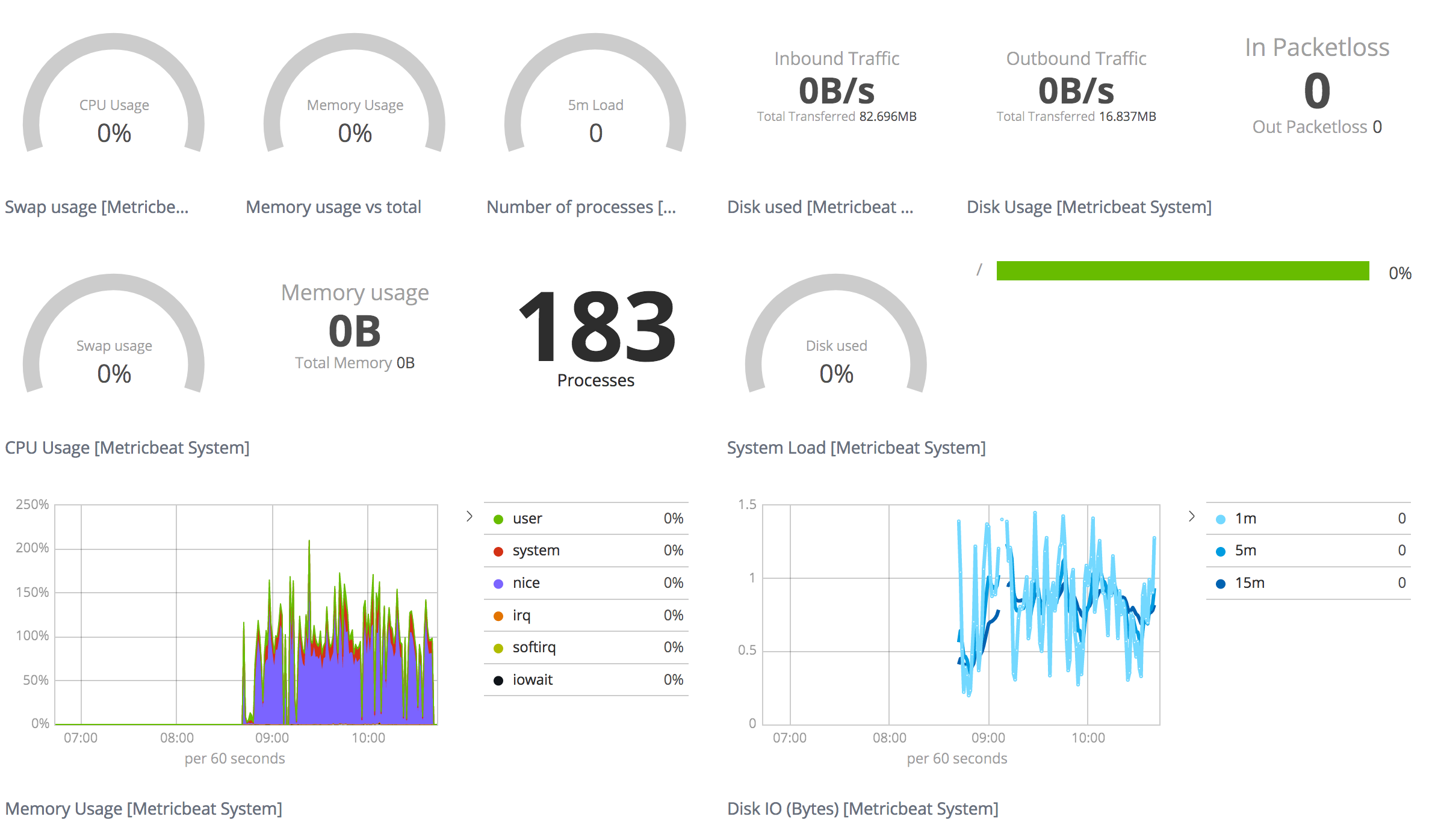
Lets try out the various options…first ensure you have an ELK stack instance you can check this digitalocean tutorial. Ensure you are getting data, try one of the various beats to monitor your system.
I set it up and now I have data:
I then set up elastalert…
Elastalert
Elastart supports only python2.7 which as we know is going / went out of support in 2020.
It is a bit tricky to set up as well, not super tricky but trick. Creating rules is also not trivial, you need to know the different rule types, the parameters they accept and they need to be tested. All these paramters are configured in yaml which developers seem to think non-technical people or even relatively technical people can use. The truth is yaml is tough and an html form with dropdowns and validation is usually better.
You pretty much have to look at the examples to try and create a rule, also querying the elasticsearch index is important.
I created a test rule after 30 minutes: rules/elasticsearch_memory_high.yaml
name: Metricbeat Elasticsearch Memory High Rule
type: metric_aggregation
es_host: localhost
es_port: 9200
index: metricbeat-*
buffer_time:
hours: 1
metric_agg_key: system.memory.used.pct
metric_agg_type: avg
query_key: beat.hostname
doc_type: doc
bucket_interval:
minutes: 5
sync_bucket_interval: true
allow_buffer_time_overlap: true
use_run_every_query_size: true
min_threshold: 0.1
max_threshold: 0.9
filter:
- term:
metricset.name: memory
alert:
- "debug"
Then I test the rule with:
elastalert-test-rule rules/elasticsearch_memory_high.yaml
We can see the matches in the stdout:
INFO:elastalert:Alert for Metricbeat Elasticsearch Memory High Rule, st2.fixes.co.za at 2019-05-28T06:40:00Z:
INFO:elastalert:Metricbeat Elasticsearch Memory High Rule
Threshold violation, avg:system.memory.used.pct 0.942444444444 (min: 0.1 max : 0.9)
@timestamp: 2019-05-28T06:40:00Z
beat.hostname: st2.fixes.co.za
metric_system.memory.used.pct_avg: 0.942444444444
num_hits: 1296
num_matches: 39
INFO:elastalert:Ignoring match for silenced rule Metricbeat Elasticsearch Memory High Rule.st2.fixes.co.za
INFO:elastalert:Ignoring match for silenced rule Metricbeat Elasticsearch Memory High Rule.st2.fixes.co.za
Working
And bang! I got it working with telegram.
Just updated my config and ran it with:
python -m elastalert.elastalert --config config.yaml --verbose --rule rules/elasticsearch_memory_high.yaml
 The only problem was it was sending this alert every minute.
The only problem was it was sending this alert every minute.
From a stackoverflow question it seemed the answer was the realert option. We don’t want the alert to be spam (that is why we did this all along)
It is very important to understand the following terms:
bucket_interval, buffer_time, use_run_every_query_size and realert.
The next thing is that you need is to run it as a service via systemd of supervisord, but I will skip this part.
I want to try the other options.
Elastalert Kibana Plugin
After setting up elastalert I realised that creating rules via yaml for non-technical people that struggle to read and apply docs will be impossible. For me it took about an hour plus debugging to figure out a single rule.
So we need a frontend that makes it easy for people to figure out and set rules for systems that they manage.
For that purpose and when still using elastalert we can use the 2 frontends available – Elastalert Kibana Plugin and Praeco. They are both in active development but Praeco is in a pre release phase.
To make use of these frontends, you need an api which apparently vanilla Elastalert from Yelp does not have. So to use these frontends we need to use the Bitsensor Elastalert fork.
Bitsensor elastalert is setup with docker according to their documentation.
I’m no docker expert but managed to sort it out, using the following steps.
Install Docker
The instructions on the docker docs site are good.
Install Bitsensor Elastalert API
The instructions on the bitsensor elastalert site did not work perfectly for me, what I did:
# Ran the recommended way
docker run -d -p 3030:3030 -p 3333:3333 \
> -v pwd/config/elastalert.yaml:/opt/elastalert/config.yaml \
> -v pwd/config/elastalert-test.yaml:/opt/elastalert/config-test.yaml \
> -v pwd/config/config.json:/opt/elastalert-server/config/config.json \
> -v pwd/rules:/opt/elastalert/rules \
> -v pwd/rule_templates:/opt/elastalert/rule_templates \
> --net="host" \
> --name elastalert bitsensor/elastalert:latest
# That created the container but it exited prematurely, this did the same thing
docker run -d -p 3030:3030 -p 3333:3333 bitsensor/elastalert:latest
# I noticed it was exiting, so checked the logs and saw that it could not access elasticsearch running on the host (not in the container)
# I needed the container to access the hosts network, which is done with https://docs.docker.com/network/host/
docker run -d -p 3030:3030 -p 3333:3333 bitsensor/elastalert:latest --network host
It still could not connect to the host using 127.0.0.1:9200, which I assume means that ip points to the container and not to the host. Debugging this is difficult though – damn I don’t want this to be a docker post. The solution looks to be connect to the hose using host.docker.internal – but there is a caveat. This only works on mac and windows, linux and production whoops.
Ah, I messed it up, jsut run the command they give and you will get a relevant error. I have elasticsearch version 6.8.0, so the latest elastalert will not work as it uses elasticseach python package for 7.0.0.
This was the error and this is the issue on github:
09:15:04.176Z ERROR elastalert-server:
ProcessController: return func(*args, params=params, **kwargs)
TypeError: search() got an unexpected keyword argument 'doc_type'
To fix that you need to build the image yourself with:
make build v=v0.1.39
But that fails with:
step 24/29 : COPY rule_templates/ /opt/elastalert/rule_templates
failed to export image: failed to create image: failed to get layer sha256:66d9b1e58ace9286d78c56116c50f7195e40bfe4603ca82d473543c7fc9b901a: layer does not exist
This was fixed by running the build again. Alas another issue is that the yelp requirements file for that version did not lock the elasticsearch version so I had to juk it with this:
RUN sed -i 's/jira>=1.0.10/jira>=1.0.10,<1.0.15/g' setup.py && \
python setup.py install && \
pip install elasticsearch==6.3.1 && \
pip install -r requirements.txt
Boom, so first step done. Next step is getting the elastalert kibana frontend plugin working:
To install it you go to: cd /usr/share/kibana/.
and then:
sudo ./bin/kibana-plugin install https://github.com/bitsensor/elastalert-kibana-plugin/releases/download/1.0.3/elastalert-kibana-plugin-1.0.3-6.7.2.zip
Only problem was that the elasticsearch version I was using 6.8.0 was not supported, so I am going to try praeco.
Praeco
This damn thing doesn’t use docker, it uses docker-compose, a different thing – an orgchestrator of docker.
which can be installed and used following these docker-compose install docs
Pull the repo then do:
export PRAECO_ELASTICSEARCH=
docker-compose up
Thing about Praeco is it includes both the bitsensor elastalert API and Praeco…damn I wasted so much time setting it up manually. Also it runs on port 8080 so try not have that port already in use on the host.
I wasn’t able to fix the issue of the docker conatainers not being able to connect to the local host elasticsearch, read the troubleshooting guide for more info. I did get it working on a remote elasticsearch.
Wow this thing is amazing…
Praeco is awesome and interactive and can be very powerful, it is still in development and has one or two bugs but overall excellent.
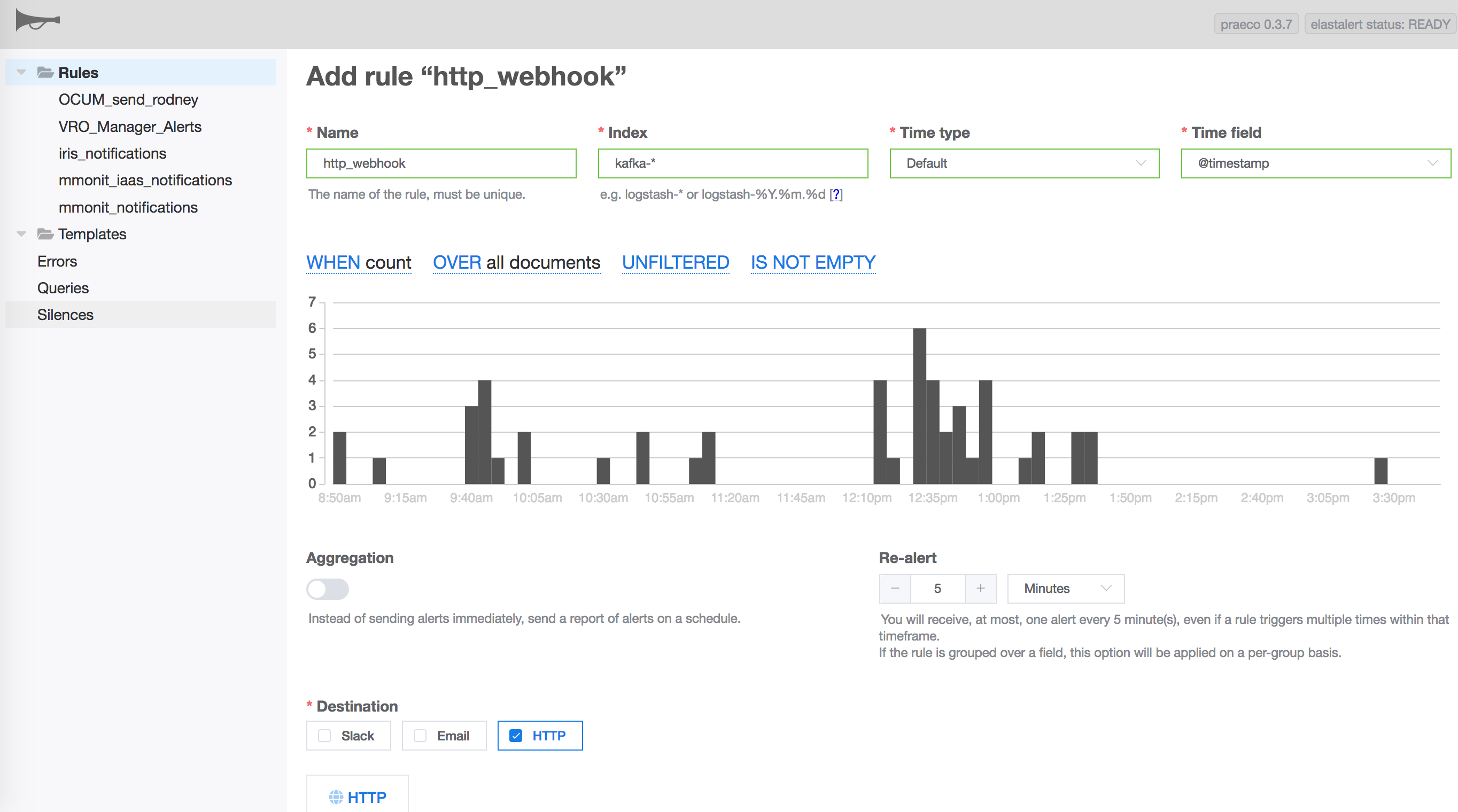
The rules are limited compared to the yaml based elastalert, but other than that it is an excellent and useful frontend.
Sentinl
Sentinl is more native to kibana, in that it plugs right in much like the existing xpack plugin.
Check you elasticsearch (or kibana) version:
http :9200
or:
sudo /usr/share/kibana/bin/kibana --version
Again the issue of compatibility rears its ugly head, where my version 6.8.0 does not have a respective release for sentinl. Only version 6.6.0 is there. Perhaps a tactic by elasticsearch?
Damn it also looks like sentinl will only be looking to support siren going forward:
Dear all, with the launch of Open Distro we feel the needs of the Kibana community are sufficiently served and as such we are focusing Sentinl on the needs of the Siren platform only.
Siren.io is an investigative intelligence platform
Even attempting to install it fails:
Attempting to transfer from https://github.com/sirensolutions/sentinl/releases/download/tag-6.6.0-0/sentinl-v6.6.1.zip
Transferring 28084765 bytes....................
Transfer complete
Retrieving metadata from plugin archive
Extracting plugin archive
Extraction complete
Plugin installation was unsuccessful due to error "Plugin sentinl [6.6.1] is incompatible with Kibana [6.8.0]"
So that is the end of that…
411
Ah the PHP and apache crew…looks ok but not something I want to look at right now. Elastalert is my guy.